Introduction
Historique:
Dans de nombreuses applications : photos satellites, clichés médicaux, photos d'agences de presse, tableaux…, un standard pour archiver ou transmettre une image fixe, en couleur et de bonne qualité est nécessaire. Une première recommandation a été donnée par l'UIT-T en 1980 pour le fac-similé, c'est à dire pour transmettre sur une ligne téléphonique une image en noir et blanc au format A4 (210 x 297 mm²) de l'ISO en environ une minute. La définition est de 4 lignes par mm et de 1780 éléments d'image (pixels, picture elements) en noir et blanc par ligne. Il y a donc environ 2 Mbits à transmettre. Pendant 1 minute à 4800 bauds (bit par seconde), on transmet environ 300kbits. Le taux de compression doit donc être voisin de 7.
Une image fixe de couleur de qualité télévision réclame de l'ordre de 8 Mbits (640 x 480 x 24). Une image de qualité 35 mm en réclame 10 fois plus. Un effort de standardisation a été effectué : l'association de deux groupes de normalisation, le CCITT et l'ISO (Organisation Internationale de Standardisation), supportée par divers groupes industriels et universitaires, donna naissance au J.P.E.G.:(Joint Photographic Experts Group). Cette norme comprend des spécifications pour le codage conservatif et non-conservatif. Elle a abouti en 1990 à une première phase d'une recommandation ISO / UIT-T. Les contraintes imposées sont importantes. La qualité de l'image reconstruite doit être excellente, le standard adapté à de nombreuses applications pour bénéficier, entre autre, d'un effet de masse au niveau des circuits VLSI nécessaires, la complexité de l'algorithme de codage raisonnable. Des contraintes relatives aux modes d'opérations ont également été rajoutées. Le balayage est réalisé de gauche vers la droite et de haut en bas. L'encodage est progressif et hiérarchique. Ces deux derniers qualificatifs signifient qu'un premier encodage peut fournir une image reconstruite de qualité médiocre mais que des encodages successifs entraîneront une meilleure résolution. Cela est utile, par exemple, lorsque l'on désire visualiser une image sur un écran de qualité médiocre puis l'imprimer sur une bonne imprimante.
La compression:
On distingue les techniques de compression conservatrice qui permettent
de reconstituer, en fin de processus, une image identique à l’image initiale,
et les techniques de compression non conservatrice. Ce sont ces dernières
qui nous intéressent ici. Elles peuvent réaliser une compression
très poussée, moyennant une certaine perte d’information. L’image
reconstituée en fin de processus diffère de l’image initiale,
mais la différence de qualité n’est pratiquement pas perçue
par l’śil de l’utilisateur.
La compression est réalisée en réduisant toutes
les formes possibles de redondance qu’une image peut présenter :
- Redondance spatiale : tous les pixels sont identiques à
l’intérieur d’une plage de l’image uniforme. Il suffit d’en coder un
pour caractériser la plage considérée. La technique de
la Transformée en Cosinus Discrète (DCT) utilisée dans
l’algorithme JPEG, met en évidence cette redondance spatiale à
l’intérieur de chaque image.
- Redondance statistique : certaines données se répètent
beaucoup plus fréquemment que d’autres. La compression sera réalisée
en attribuant des codes d’autant plus courts que la fréquence est élevée.
- Redondance subjective, mise à profit dans la compression
non conservatrice : elle découle des imperfections de l‘śil humain.
Des pixels présentant des caractéristiques assez proches pour
être perçus de manière identique peuvent être traités
comme des pixels identiques.
On peut noter que l’śil est beaucoup plus sensible aux variations
d’intensité lumineuse (luminance) qu‘à celles de la couleur (chrominance) :
les informations sur la couleur peuvent donc être davantage compressées
que celles sur la luminance. De même, des pixels trop proches pour être
distingués par l‘śil peuvent être regroupés (il suffit de
520 lignes sur un téléviseur pour donner une image assez correcte).
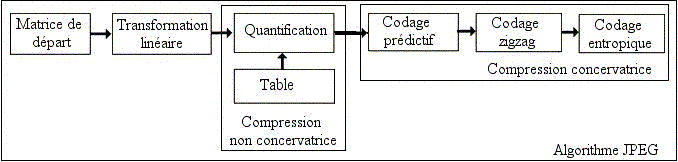
Principe du codage JPEG:
Le principe de la compression JPEG consiste à supprimer les détails les plus fins d'une image (ceux que le système visuel humain ne peut détecter).
Pour une image à niveaux de gris (une image couleur est un ensemble d'images de ce type), la suite d'opérations à effectuer est la suivante:
- Une image est décomposée séquentiellement en blocs de 8x8 pixels subissant le même traitement.
- Une transformée en cosinus discrète bi-dimensionnelle (DCT) est réalisée sur chaque bloc (notion complexe).
- Les coefficients de la transformée sont ensuite quantifiés uniformément en association avec une table de 64 éléments définissant les pas de quantification. Cette table permet de choisir un pas de quantification important pour certaines composantes jugées peu significatives visuellement.Une table type est fournie par le standard mais n'est pas imposée.
- Un codage entropique, sans distorsion, est enfin réalisé permettant d'utiliser les propriétés statistiques des images. On commence par ordonner les coefficients suivant un balayage en zigzag pour placer d'abord les coefficients correspondant aux fréquences les plus basses. Cela donne une suite de symboles. Le code de Huffman consiste à représenter les symboles les plus probables par des codes comportant un nombre de bits le plus petit possible.